



Last time, we argued that agentic AI is structurally deflationary for SaaS. But that only holds if the agent is consistent, auditable, and able to operate over time without re‑asking the same questions or repeating the same mistakes. That takes us to the real infrastructure question behind the SaaS compression narrative: Memory. As clients start underwriting agents as systems of record for decisions and actions—not just assistants—many are now focused on the next market: the memory/state layer that makes agents dependable, and how large that spend category can become.
In the last 4-6 months, the questions we’re getting from clients have shifted from “can the agentic model answer this?” to “can the agent run the workflow end‑to‑end, reliably, repeatedly, and at a predictable unit cost? What’s infrastructure behind them?”
In practice, that immediately turns into a memory problem: why does the agent re‑ask the same clarifying questions, forget constraints mid‑task, or behave inconsistently across sessions? And once agents move beyond a single response into minutes‑long or even tens‑of‑minutes execution, memory stops being a “nice feature” and becomes the substrate for continuity, auditability, and control.

Recent market data confirms that the value capture in the AI stack is shifting upstream to the component level. As highlighted by financial reporting on the “AI Memory Boom”, memory manufacturers like SK Hynix and Kioxia are seeing valuation surges exceeding 1,000%—outperforming even the logic designers. This “supercycle” is driven by the acute shortage of HBM3e (High Bandwidth Memory), which is now the primary constraint on GPU/TPU production.
While hyperscalers (Google/Meta) and chip designers (NVIDIA) fight for dominance, the memory fabs have secured effective pricing power, with production sold out years in advance, effectively turning HBM into the industry’s most scarce commodity.
Other Data points that explain why memory is suddenly first‑order (not optional):
Tokens = COGS, and re-deriving context is expensive at scale. Anthropic’s pricing guide uses a support-agent example with ~3,700 tokens per conversation and estimates roughly ~$37 per 10,000 tickets (example math depends on model/pricing tier), illustrating how quickly costs compound when the system repeatedly re-loads history instead of remembering key decisions.
Agents are now designed to run for “several minutes” to “tens of minutes,” which forces durable state (memory) and job semantics. OpenAI’s docs explicitly position Background mode for long-running tasks and note that agentic systems can take several minutes, while “Deep research” tasks can take tens of minutes

Source: Open AI
Cloud platforms are explicitly monetizing memory/session primitives, which is a strong signal that the market is treating memory as core infrastructure. Google’s Vertex AI Agent Engine/Agent Builder materials indicate Sessions and Memory Bank (along with Code Execution) moving to metered billing starting Jan 28, 2026 (per pricing/release notes).
Taken together, these developments show memory moving from an implementation detail to a monetized, governed infrastructure layer—the prerequisite for agents that run longer, cross tools and models, and operate inside regulated enterprises.
Per Mordor, The Agentic AI Orchestration And Memory Systems Market size is estimated at USD 6.27 billion in 2025, and is expected to reach USD 28.45 billion by 2030, at a CAGR of 35.32% during the forecast period (2025-2030).
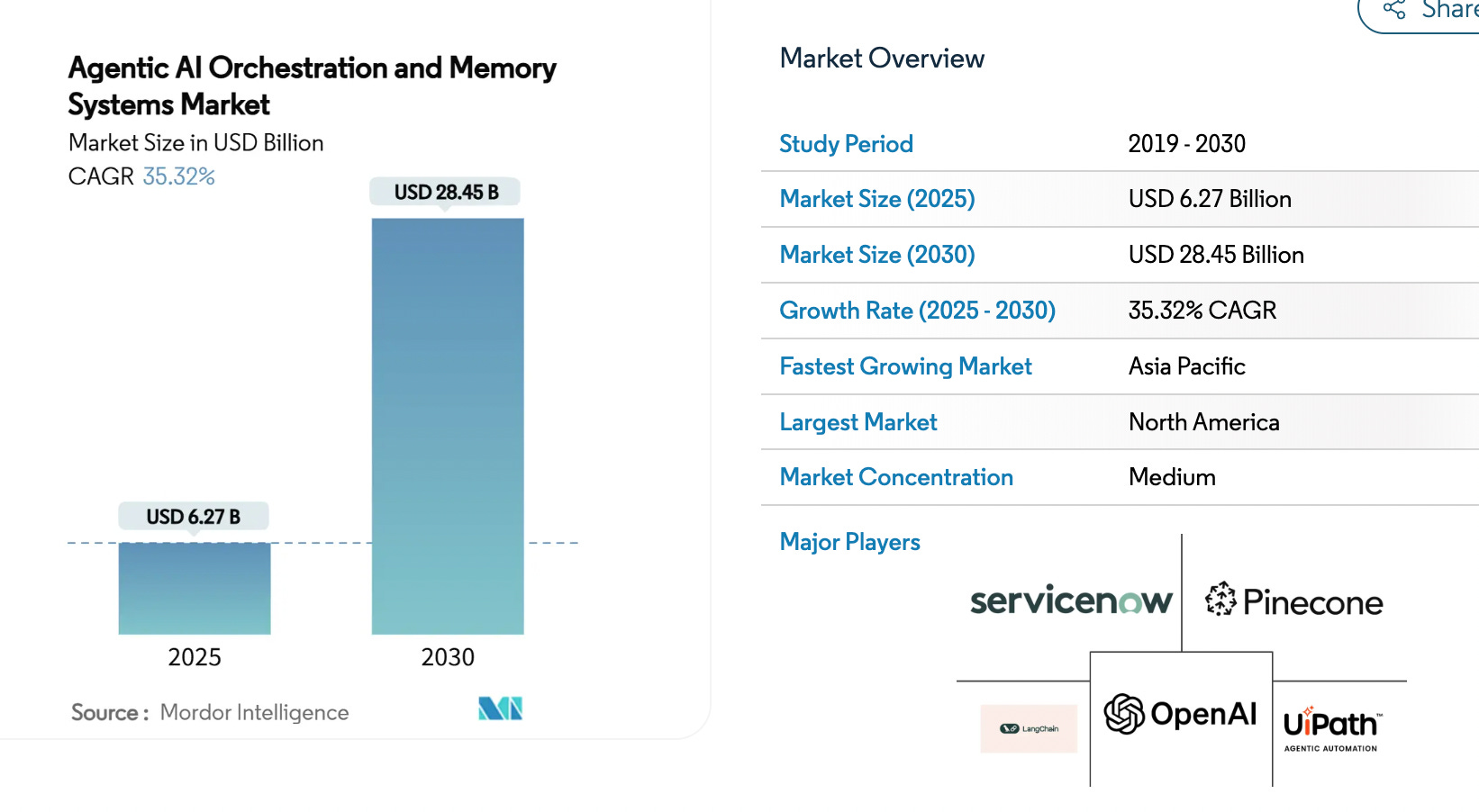
Source: Agentic AI Orchestration And Memory Systems Market
In today’s article, we’ll address these client asked questions related to Memory and Agentic AI Infrastructure:
AI agent memory infrastructure: What is AI agent memory infrastructure, and how do its different memory layers change the overall demand for memory across the stack? Why do multiple memory layers are required?
Build vs buy (memory/state infra): When should an AI infrastructure company build its own memory/state layer vs adopt a vendor—and what are the hard gates that decide the answer?
Pilot, Growth and Large Scale Scenarios with Bedrock AgentCore Memory pricing vs. Build in-house
Analysis of Menlo and Battery’s reports and takeaway
Architecture + tokens (state placement in a token-priced world):
(Token ROI): In a token‑priced world, how should teams budget tokens across instructions, retrieved context, state, and tool outputs—especially for long‑horizon agents where “more context” can increase cost and reduce reliability?
(DeepSeek tie): If model efficiency keeps improving (e.g., DeepSeek‑style cost/perf shifts), what changes in the infra playbook: more on‑prem/on‑device inference, bigger working contexts, different caching strategies—or does “state outside the model” still dominate for correctness?
Who’s leading: Which players are leading in agentic infrastructure memory?, and what have recent projects/launches demonstrated about what really works at scale?
Please note: The insights presented in this article are derived from confidential consultations our team has conducted with clients across private equity, hedge funds, startups, and investment banks, facilitated through specialized expert networks. Due to our agreements with these networks, we cannot reveal specific names from these discussions. Therefore, we offer a summarized version of these insights, ensuring valuable content while upholding our confidentiality commitments.
Q1. AI agent Memory Infrastructure: Why Multiple Memory Layers Are Required?
Over the past year, the conversation around agentic AI has shifted from model quality to operational durability. Investors are no longer asking whether agents can generate text—they’re asking whether agents can run workflows, maintain continuity across sessions, survive failures, and operate under governance constraints. That shift brings one infrastructure layer to the center: memory. In agentic systems, memory is not about “remembering a chat”—it is the mechanism that makes behavior consistent, enforceable, and economically scalable.
AI agent memory infrastructure refers to the systems and patterns that enable an AI agent to store, retrieve, manage, and reason over persistent knowledge across interactions, contexts, and tasks. Memory allows agents to behave statefully—remembering facts, preferences, plans, past interactions, world state, and long-term learning outcomes.
For production-grade agents (e.g., in enterprise automation, ITSM, knowledge work agents, robotics), memory infrastructure is a foundational capability that supports:
Context continuity: retaining user or environment history across sessions
Personalization: storing user preferences and profiles
Causal reasoning: chaining past events into current decision-making
Long-term planning & learning: accumulating experience and improving over time
Knowledge grounding: integrating domain knowledge, databases, and ontologies
Memory infrastructure is not just a datastore; it’s a multi-layered retrieval and reasoning system.
Let’s look at the diagram below and walk thorugh an example to understand this better.
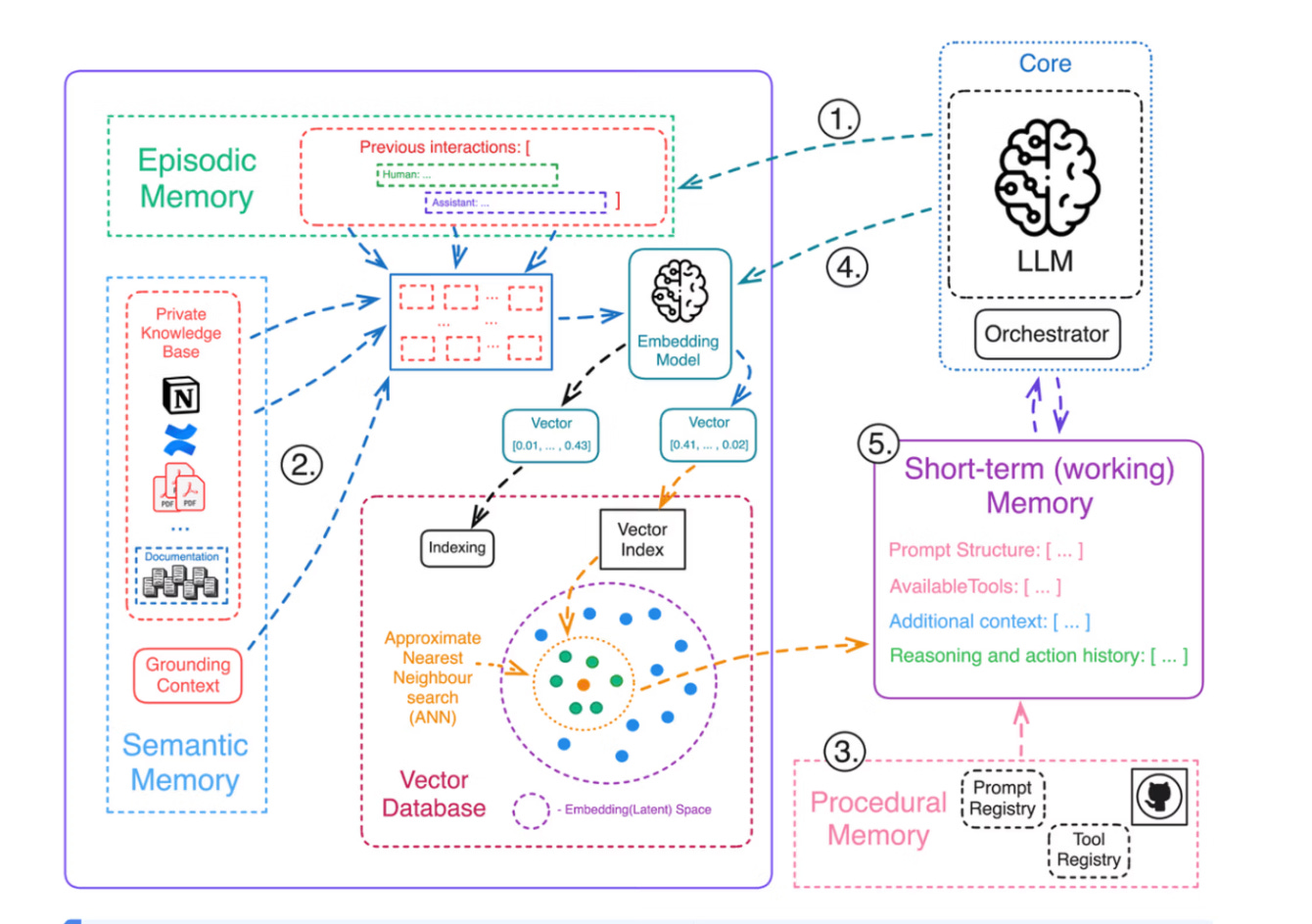
Source: Agentic Memory Aurimas
To understand above, let’s run this diagram through a typical Agentic AI user request. Let’s say our user request is:
“Schedule ‘Tech Deep Dive’ on Dec 31 for 60 minutes. It must be at least 30 minutes after Marcus’s ‘Code Review Session’ and at least 30 minutes before any event I already have.”
