
What OpenAI’s $250M NewsCorp Deal Signals & Perplexity–TIME Rough Revenue Uplift Analysis


Between 2022 and 2025, licensing data for AI model training evolved from a niche practice into a standard industry paradigm. In 2024, Reddit’s COO noted that Reddit’s agreements with Google and OpenAI already comprised ~10% of the company’s revenue, underscoring how significant this new revenue stream became for data-rich platforms.
At the high end, the News Corp–OpenAI deal (announced in 2024) is reportedly worth more than $250 million over five years. OpenAI didn’t just buy headlines—they licensed revenue retention. The News Corp deal marks a new era where quality content becomes recurring margin in the AI stack

Another one,

That $16M is only the fixed minimum – the deal includes a variable component that could boost payments further based on how the content is used.
As of now, most leading AI firms had inked multi-year data agreements with content providers, and many publishers saw licensing as a material revenue line. In short, a “data sharing economy” has emerged, in which content owners monetize their archives and real-time data, while AI companies secure the reliable, proprietary datasets needed to train and enhance AI models.
Later in this post, we will break down a directional revenue model for TIME’s partnership with Perplexity.ai—one of the first AI-native search engines offering ad revenue sharing to publishers. While the numbers are built on public traffic estimates and industry benchmarks, they offer a pragmatic lens into how premium publishers could begin to monetize their content in AI-driven environments.
It’s not perfect math, but it’s a solid directional framework for investors looking to understand where the upside lives in this evolving content stack.
This article will go through the AI Companies and Media Partnership landscape, breaking down:
AI Data & Content Ecosystem & Players
Most Valuable Types of Data for GenAI Training
Breakingdown players in three categories: 1 . Scarce upstream IP rights players 2 . Players benefit margins from expert labor & labeling tech & 3 . Toll booth and audit-as-a-service players
Why Content Originators Are Becoming Critical Infrastructure
Rise of licensing deals (News Corp, Reddit, etc.)
Breakdown of which AI companies are aligned with which publisher
Buying the Moat: AI–Media Licensing Model is Maturing in 2025
Various Contract structures & pricing
OpenAI & NewsCorp contract structure
Who Gets Paid When AI Scales?
Attribution-driven traffic + rev share (e.g., Perplexity.ai’s model) is getting traction
Perplexity–TIME revenue uplift analysis
Please note: The insights presented in this article are derived from confidential consultations our team has conducted with clients across private equity, hedge funds, startups, and investment banks, facilitated through specialized expert networks. Due to our agreements with these networks, we cannot reveal specific names from these discussions. Therefore, we offer a summarized version of these insights, ensuring valuable content while upholding our confidentiality commitments.
AI Data & Content Ecosystem & Players
While the generative AI boom has triggered massive investment into model development, it's important to distinguish between two fast-growing but fundamentally different markets: AI Data and Content licensing and AI training/fine-tuning dataset spend. The data licensing market refers specifically to payments made by AI companies to content owners—such as publishers, platforms, and forums—for legal access to their proprietary text, images, or metadata.
In contrast, training and fine-tuning dataset spend captures the entire end-to-end cost of making data usable for models. This Market includes companies providing data annotation, curation, synthetic data, AI model training, and evaluation. We expect this broader dataset operations market could surpass $30 billion annually by 2030, particularly as enterprises fine-tune foundation models for domain-specific use.
We will look at AI Data and Content Market for this article.
To understand how the generative AI economy is forming around data, we need to first map the emerging ecosystem of content and infrastructure players shaping the flow of information into foundation models.
The AI content ecosystem is evolving into a structured value chain, with distinct upstream and downstream roles. At the foundation are 1. Content & Signal Originators—publishers, platforms, and API providers whose data powers generative models through training or retrieval. Sitting above them are 2. Data Enrichers like Scale AI and Surge AI, which convert raw content into high-quality training assets via labeling, alignment, and filtering.
Finally, 3. Licensing Infrastructure players—like Prorata or API brokers—are emerging as gatekeepers, enabling monetization, compliance, and rights orchestration. For investors, this stack highlights where durable moats, pricing power, and second-order data royalties may emerge in the GenAI economy.
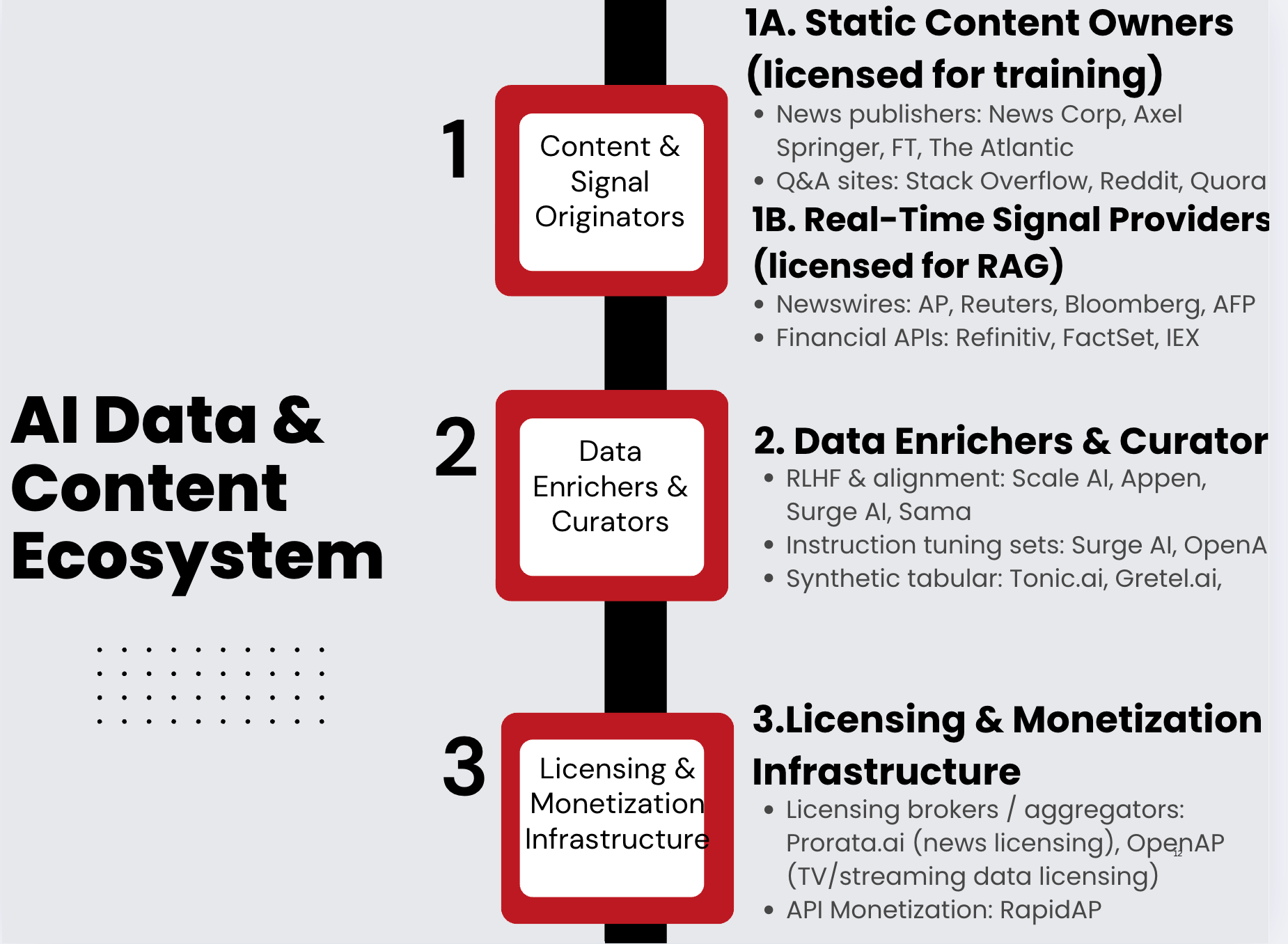
For hedge funds and private equity firms, the maturing AI content ecosystem creates investable opportunities across all three layers of the stack. At the top, scarce content rights holders—like publishers, Q&A platforms, and financial APIs—are turning into recurring revenue engines through licensing, making them prime for cash flow extraction or roll-up strategies.
In the second layer, data enrichers and RLHF platforms like Scale AI, Appen, and emerging synthetic data startups offer high-margin, defensible infrastructure plays—essential for fine-tuning and safety alignment in models. Finally, the third layer—licensing and monetization infrastructure—represents a greenfield opportunity. Firms like Prorata.ai are creating the plumbing for data revenue flow, much like ASCAP or BMI did for music, and may evolve into tollbooth-like assets in the GenAI value chain. For investors, the play isn't just the model builders—it's the upstream and infrastructure providers who will extract value every time a model trains, responds, or monetizes.
When an AI model company is looking to license or buy data, they don’t just ask, “How much data is available?”—they ask, “What kind of data will make our model meaningfully better for specific use cases?” The goal isn’t raw scale anymore—it’s strategic data that improves output quality, safety, factual grounding, and domain-specific reasoning.
For general-purpose LLMs, companies seek high-quality language data that helps the model write more fluently, reason better, and minimize hallucinations. This often includes well-edited, factual, and stylistically diverse text: think journalistic content, encyclopedic entries, academic papers, and books with narrative structure. But as the market matures, the focus is increasingly shifting to specialized and proprietary datasets—especially enterprise content.
One of our clients asked: What types of data are considered most valuable for AI companies to acquire or license—and how do those companies evaluate what’s worth paying for?
