
The AI Storage Market Investors Are Modeling Wrong: Capacity Still Matters, but Utilization Matters More


The AI market still tends to treat storage as a passive byproduct of AI buildout — more GPUs, more data, more capacity. But that framing is already getting stale. McKinsey expects inference to surpass 50% of AI workloads by 2030, while Deloitte expects inference to account for roughly two-thirds of AI compute in 2026.
Once that happens, the storage problem changes. The bottleneck is no longer just how many bytes you can hold. It becomes where data sits, how fast it moves, how often it is reused, and whether it is feeding or starving very expensive compute.
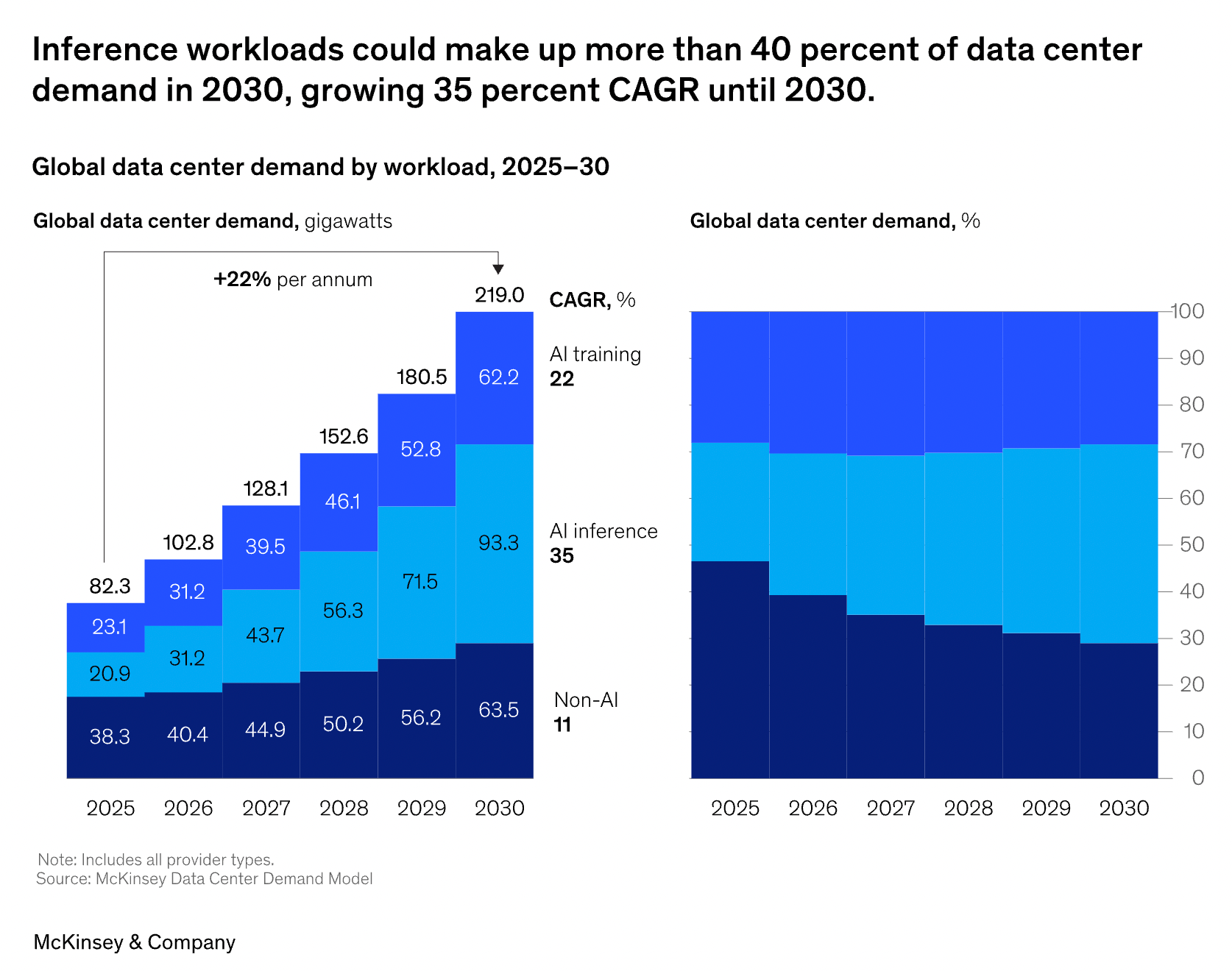
Source: The future of AI workloads report
That is why the wrong question is “who sells more storage?” The right questions are much narrower — and much more investable. Which workloads can still live on centralized object and warehouse architectures? Which ones require file, cache, vector, or compute-local storage? Where does flash actually earn its premium, and where does disk still win on economics? And most importantly, when does a storage redesign move the compute line item, not just the storage line item? Per Omdia report, data management has already become a top-two challenge for organizations deploying AI workloads.

The three questions below are to separate signal from noise straight from clients’ desks. They are not meant to be a laundry list of vendor opinions. They are meant to answer the operating-model question first, the capital-allocation question second, and the ROI question last. In other words: how should investors think about AI storage by workload, by media, and by economic threshold? That is the lens that matters more than any single product launch or architecture diagram.
Storage Operating Model by Workload: How should AI customers architect storage differently for training vs. inference vs. eval workloads?
Which workloads remain well-served by centralized / warehouse architectures?
Which workloads require file, cache, vector, or compute-local storage?
Where do vendors fit in the stack?
SSD vs. HDD Capital Allocation (Where Dollars Go): Which AI workloads actually justify flash, and where does disk still win?
Performance-sensitive workloads and Capacity-heavy workloads
Vendor exposure — Micron for flash vs. Seagate / Western Digital for HDD
ROI Calculator for AI Storage Redesign: When does a storage redesign move the compute line item, not just the storage line item?
Case A — Frontier Training Cluster
How much ROI comes from improving checkpoint efficiency and GPU feed performance on a multi-thousand-GPU training fleet?Case B — Revenue-Critical Inference / RAG System
How much ROI comes from lowering p99 latency and reducing the number of serving GPUs required to hit a production QPS target?Case C — Hybrid Enterprise AI Stack
When does a storage redesign remain mostly qualitative—better governance, cleaner architecture, less operational risk—rather than generating obvious hard-dollar savings?
Please note: The insights presented in this article are derived from confidential consultations our team has conducted with clients across private equity, hedge funds, startups, and investment banks, facilitated through specialized expert networks. Due to our agreements with these networks, we cannot reveal specific names from these discussions. Therefore, we offer a summarized version of these insights, ensuring valuable content while upholding our confidentiality commitments.
Q1. Storage Operating Model by Workload
The first question is the most important one because it sits above all the vendor noise. Before investors decide whether Snowflake, Databricks, Weka, VAST, or Pure are the right read-throughs, they need to understand the underlying operating-model shift. The core issue is simple: AI does not create one storage problem; it creates several different ones depending on whether the workload is training, inference, evaluation, or some hybrid enterprise workflow. That is why the old assumption—that one centralized data layer can serve every AI workload equally well—is starting to break.
In Deloitte’s Tech Trends 2026 report, Dell’s CTO explicitly argues against retrofitting legacy "brownfield" enterprise environments for AI. He defines the required architecture for an "AI factory," explicitly stating that the "storage environment is really a knowledge layer: vector databases, graph databases, knowledge graphs, context-aware chatbots, and data pipelines

Source: Page 37 in Deloitte 2026 Report
In traditional IT, storage was a passive archive built for batch retrieval. You dumped documents, logs, and tables into centralized data lakes (like an AWS S3 bucket) and queried them at your leisure.
In the “Knowledge Layer” (Inference-Era), inference demands context delivered at the speed of thought. A “knowledge layer” means the storage itself is an active, ultra-low-latency semantic engine. As Roese notes, this involves purpose-built vector databases and in-memory knowledge graphs. When a user submits a prompt, the vector database instantly streams the exact mathematical context directly into the LLM’s context window. The GPU doesn’t have to search—it just executes. This sub-millisecond data delivery is the only way to achieve scalable, low-latency inference without bleeding capital on idle compute.
Workload types
it helps to break AI workloads into four buckets: training, inference / RAG / agents, eval / post-training, and hybrid enterprise AI. Each bucket has a different storage pattern, a different failure mode, and a different threshold at which centralized storage stops being good enough. The table below is meant to answer the operational question directly:
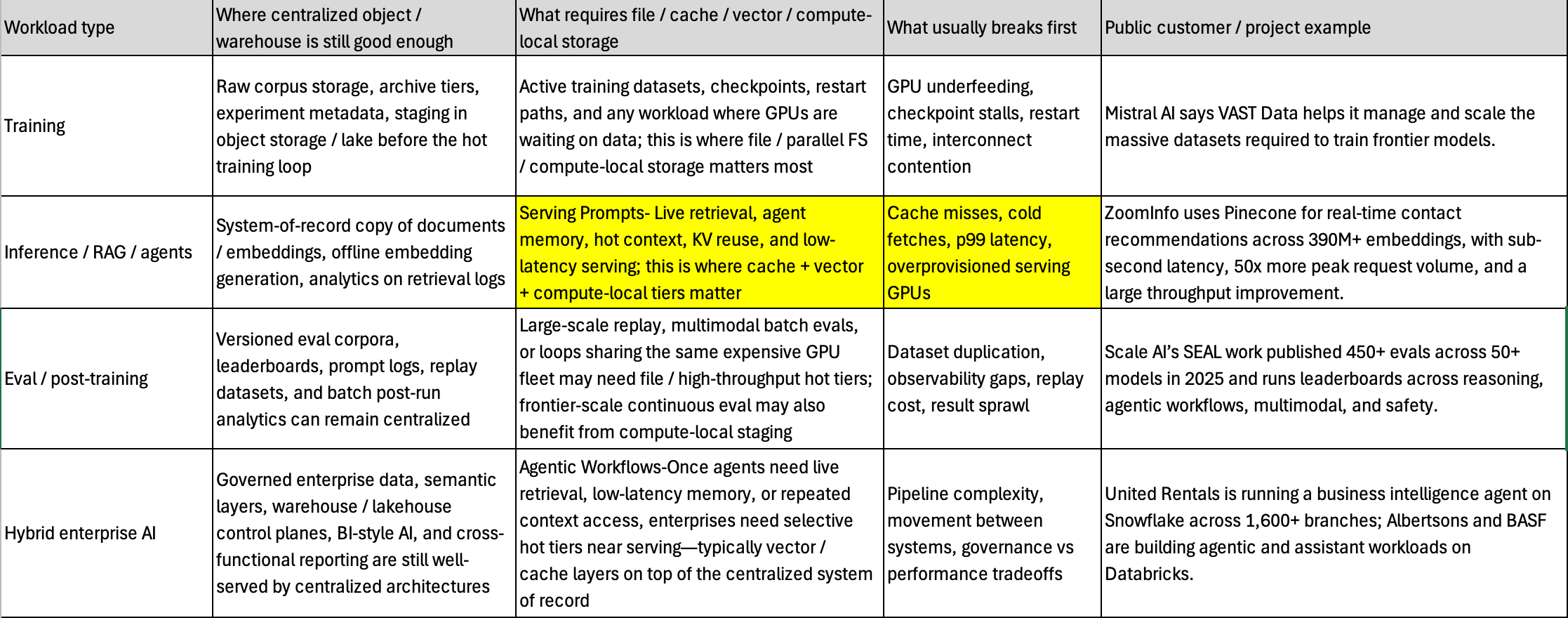
Inference is different.
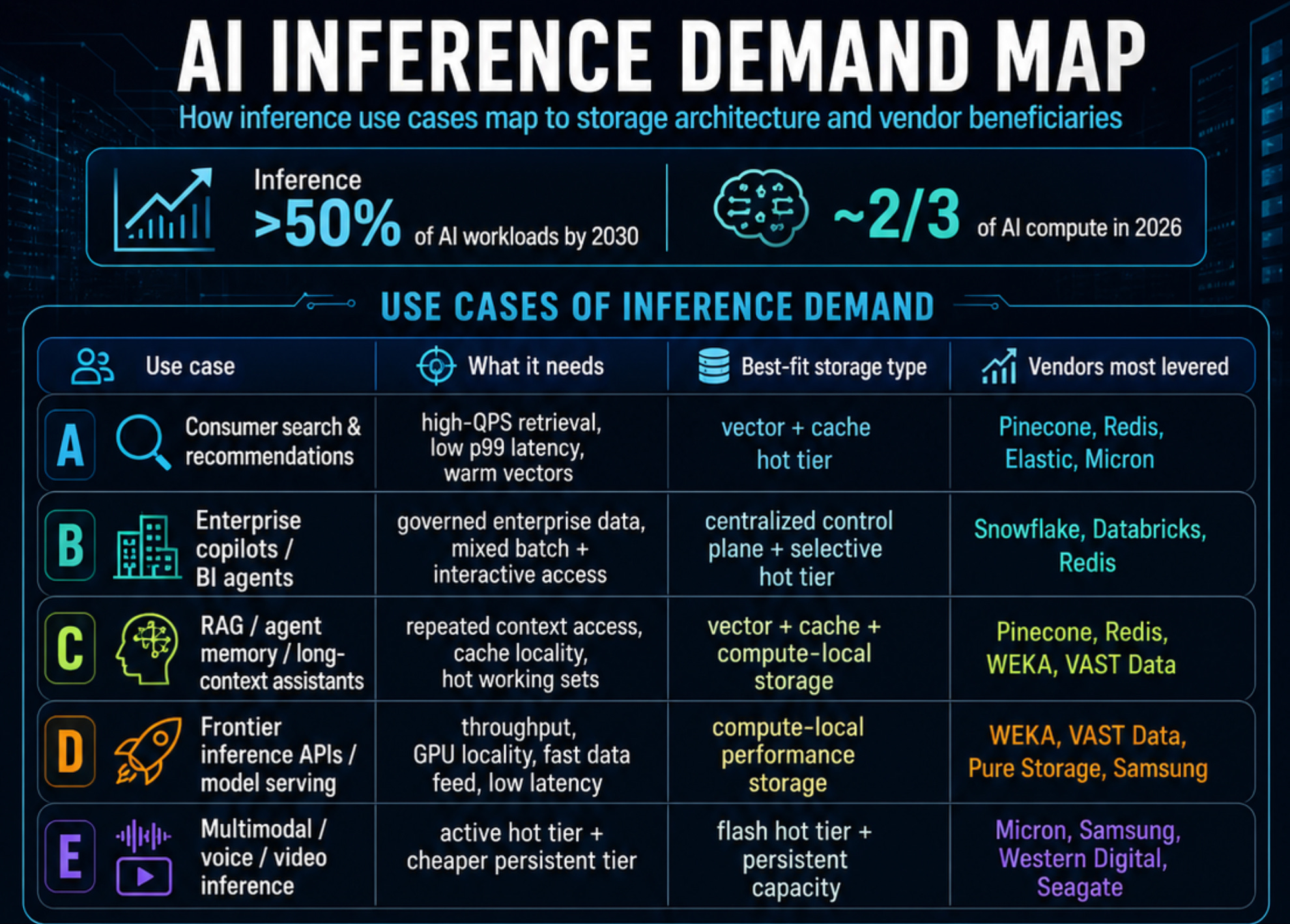
Inference demand should not be treated as one storage category. Consumer recommendations, enterprise copilots, RAG, agent memory, frontier model serving, and multimodal inference all stress storage differently. Some workloads need governed enterprise data and a centralized control plane; others need low-latency retrieval, cache locality, vector access, or compute-local storage close to GPUs.
The storage stack therefore splits into multiple layers. Snowflake and Databricks remain relevant where enterprise AI is governed, structured, and pipeline-centric. Pinecone, Redis, and Elastic become important when retrieval, RAG, and agent memory sit in the live request path. WEKA, VAST Data, and Pure Storage matter when storage directly affects GPU throughput, checkpointing, and low-latency inference. Micron and Samsung benefit from hot memory and flash intensity, while Western Digital and Seagate remain exposed to persistent AI data: logs, replay datasets, archives, model artifacts, and colder AI exhaust.
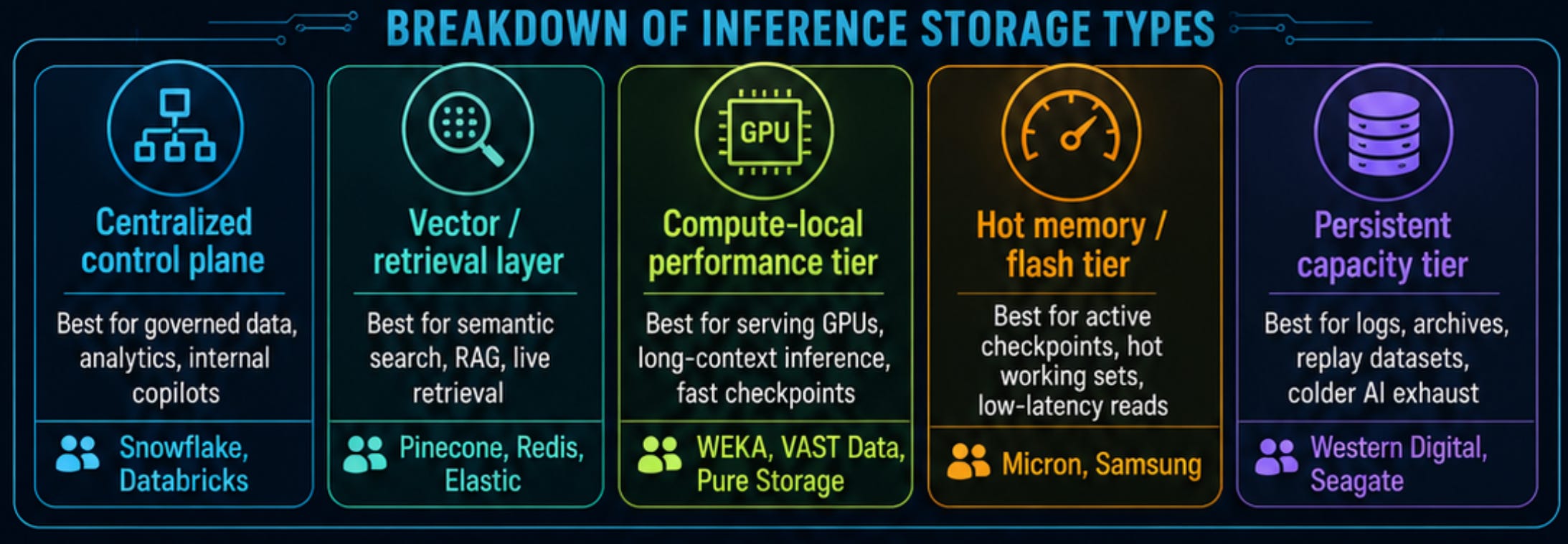
The key investor takeaway is simple: inference is not one storage market — it is a stack. The winners are the vendors that keep data close to compute, reduce p99 latency, improve retrieval performance, or shrink the serving fleet. As inference becomes a larger share of AI economics, storage becomes less about holding bytes and more about making expensive AI infrastructure productive.
