


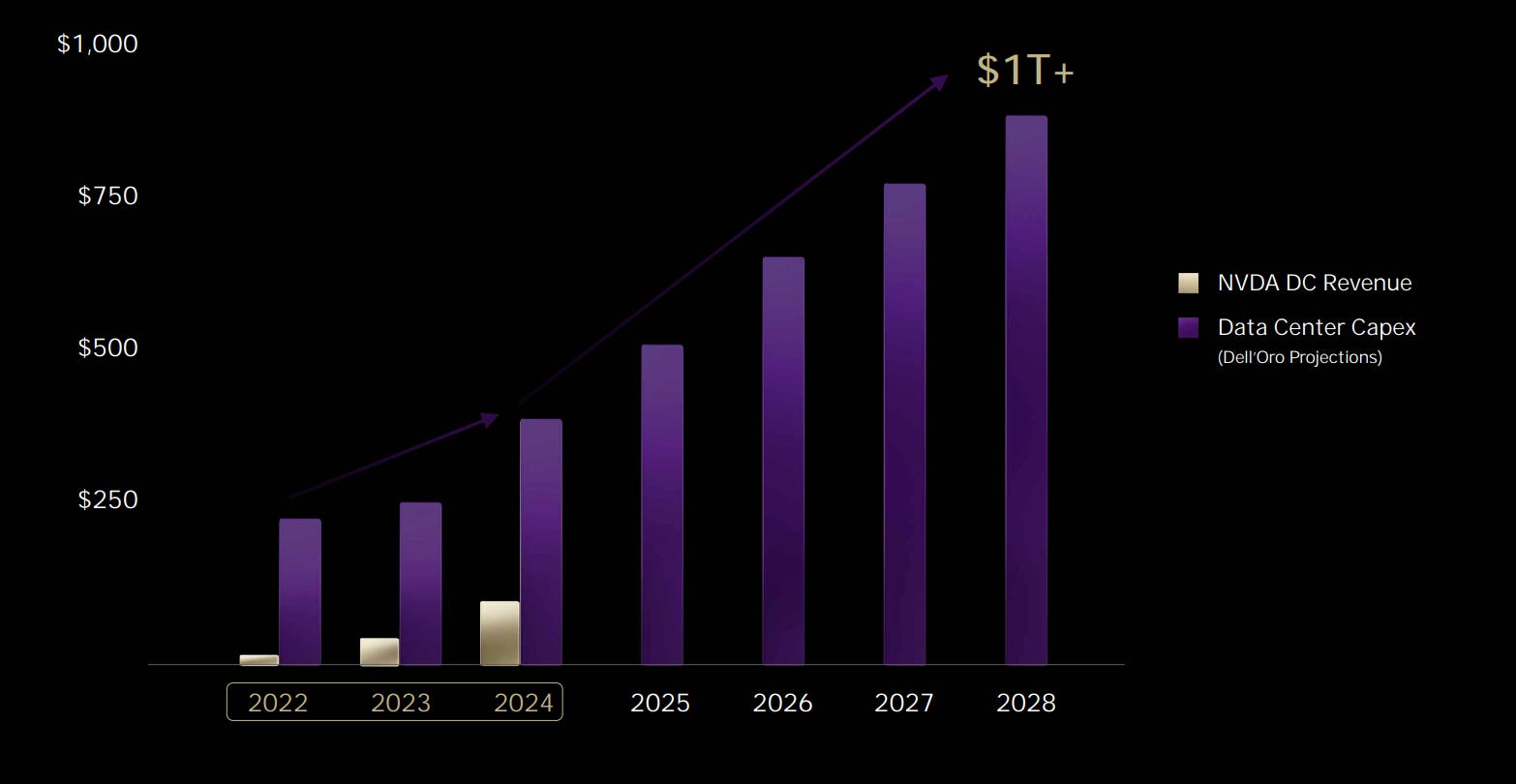
At GTC 2025, Nvidia emphasized that we are at an inflection point in computing, where AI data centers are becoming the new factories of the digital age. CEO Jensen Huang highlighted that Data Center CapEx is projected to exceed $1 trillion by 2028, reflecting the massive investment into AI infrastructure by hyperscalers.
Source: GTC NVDA 2025
While DeepSeek has shown that AI models can be trained with fewer GPUs and at lower cost, one might expect this to slow the overall growth in AI compute demand. However, the data tells a very different story.
According to another 650 Group report, companies spent over $200 billion on AI hardware in 2024—an all-time high—driven by the rapid adoption of generative AI, hyperscaler expansions, and enterprise AI deployments. This raises an important question: If DeepSeek's advancements in model efficiency were meant to reduce GPU dependency, why is AI hardware spending still skyrocketing?
In a world where AI models are becoming more sophisticated, multimodal, and reasoning-driven, clients are asking critical questions: How much compute is enough? More specifically,
How many GPUs are being used for inference? Are custom AI chips (TPUs, Trainium, Maia AI) reducing dependence on Nvidia hardware?
What does the 2025–2027 roadmap for AI compute look like across hyperscalers?
This blog explores the post-DeepSeek demand landscape, breaking down:
Contrasting the Pre-DeepSeek vs. Post-DeepSeek
Why Efficiency Gains From DeepSeek haven’t Slowed the AI Compute Boom?
AI Compute Deployment Forecast by players: GPUs & ASICs (2024–2026E)
Players: Microsoft,Google, Meta, Amazon, xAI (Elon Musk startup)
AI Inference Demand Forecast By Use Cases (2024–2027E)
Use Cases: Chatbots & Assistants, AI Agents, Video & Image AI, Enterprise AI and Autonomous Systems
Please note: The insights presented in this article are derived from confidential consultations our team has conducted with clients across private equity, hedge funds, startups, and investment banks, facilitated through specialized expert networks. Due to our agreements with these networks, we cannot reveal specific names from these discussions. Therefore, we offer a summarized version of these insights, ensuring valuable content while upholding our confidentiality commitments.
